Hi community,
Sharing with you our progress of the past two months.
Our long term vision is to build a decentralized data analytics product with a new biz model to compete with (and do better than) centralized data analytics platforms such as chainanalysis, nansen, dune. To get there, the first question that we try to answer is whether we can recreate what has been built on these centralized platforms.
The answer is yes but very tricky at this moment.
Let me walk you through a simple NFT dashboard we try to recreate from Nansen. Nansen has a feature called “24H NFT Market Overview” (which requires $149/month to access). It tracks the past 24 hours market information of the popular NFTs on Opensea.

Here is our demo and the obstacles we have run into:
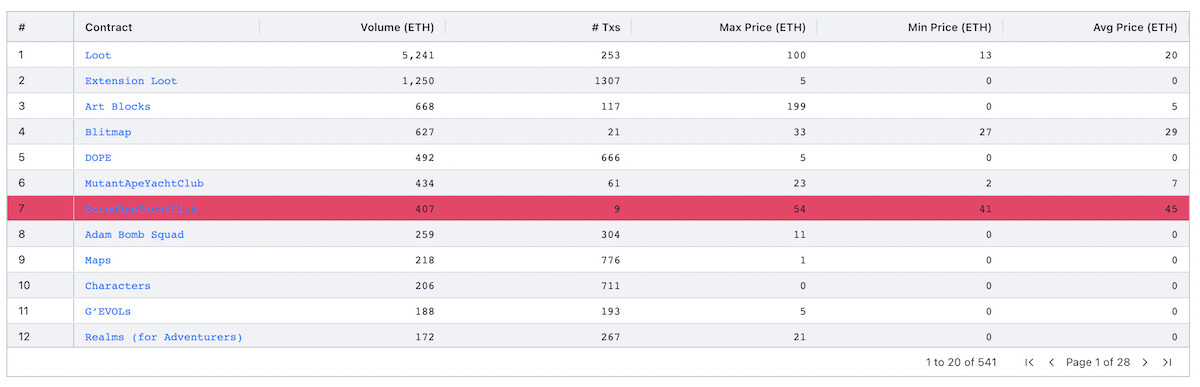
-
Throughput limitations: It takes very long time to load just 6 hours worth of data.
-
Missing log index in the transaction model. It would be very tedious to recreate the “%Opensea+Rarible” column if we don’t have this feature. In order to identify whether this NFT was transacted on the opensea or rarible platforms, we need to access the logs index section of the transaction model to locate that specific log which is associated with an opensea or rarible exchange smart contract.
-
“Marketcap column”. In order to calculate the latest market cap (to sum up the sales price of each token in an NFT collection), we need to get the history of all the token sales. Then we need to periodically pre-calculate and store the latest prices in a subgraph. Our subgraph only syncs data since September and it is still not done yet. (It has been 4 days and it has only synced additional 10k blocks)
-
“#Wallet”. We have no way to tell whether if an address is a wallet or contract. Although web3.js has a way to tell but we are not allowed to use any 3rd party libraries when indexing subgraphs.
-
Our demo only contains EIP721 compatible NFT transactions. For EIP1155 compatible NFTs, we found an almost perfect subgraph but it does not have the ETH transferred value per transaction that we need. In order to use it, we would need to modify its code, redeploy and sync the subgraph. Then we would run into the same issue mentioned in 3.
-
Fetching off chain data. For some of the ERC721 tokens and all ERC1155 tokens, it would be ideal to read their metadata, such as names, rarity data. Here is an example:
This is an NFT on Opensea:
https://opensea.io/assets/0x495f947276749ce646f68ac8c248420045cb7b5e/4981676894159712808201908443964193325271219637660871887967795137569907277825
And we would like to get its metadata from here:
https://api.opensea.io/api/v1/metadata/0x495f947276749Ce646f68AC8c248420045cb7b5e/4981676894159712808201908443964193325271219637660871887967795137569907277825
To do so, we need to use async functions to fetch data which is currently prohibited by the graph compiler. We have raised this issue in this forum post
Proposing to make more diverse subgraphs. Need your feedback